About 8 months ago I ran my work application through nDepend to see what kind of disaster we really had on our hands. The results provided a very deep insight into the current state of our application and certainly reaffirmed the thoughts on refactoring that we had been having. After a few months of steady refactoring, mixed with a switch from .NET 1.1 to 2.0, I again ran the solution through nDepend to see if it would confirm my belief that we had actually made a difference. To my relief, there was a noticeable difference in the results (luckily for me they were good differences).
It didn’t take me to long to realize that in our refactoring efforts we had made numerous changes and had more rigorously adhered to some good OO principles, but we had done it all at once. I was left wondering which of those changes made the biggest difference? Being that this was my first attempt at rescuing software from the brink, I really wanted to know. I needed to know so that I could better apply my lessons learned on the next project (don’t they all seem like they’re on the brink when you first show up?).
Out of that curiosity I decided to build a series of demonstration solutions that took the same code base and progressively applied the changes I had tried to at work. I wanted to see what happened after every step in the process. In the end I’ve ended up with the following six solutions:
- Base Code – this is the disaster that you have inherited or created
- Interface Based Programming – take the disaster and interface everything
- Single Responsibility – clean up the concerns that exist in the current classes
- Poor Man’s Dependency Injection – apply some DI to your code
- Roll Your Own Inversion of Control Container – This one isn’t pretty but it can be done
- Castle Windsor – implement Windsor IoC where you had the Roll Your Own IoC
Throughout the evolution of the code as I moved through these solutions I did a couple of things. First, I ensured that I always had tests that passed. Everyone of these solutions is as fully tested as it could be. This means that you can also see the how the testing techniques changed as the coding style changed. Second, the functionality of the code never changes. In the sixth solution you have the exact same results as in the first.
What I was hoping to see when this experiment was over was that there would be a significant increase in the cohesion and a significant decrease in the coupling. I also wanted to see if I could manage similar results with a very small code base as I did with the large code base at work. Here’s the tail of my code’s evolution.
If you don’t want to read the rest of this (I have a feeling it’s going to get quite long), you can download the source here.
The Base Code
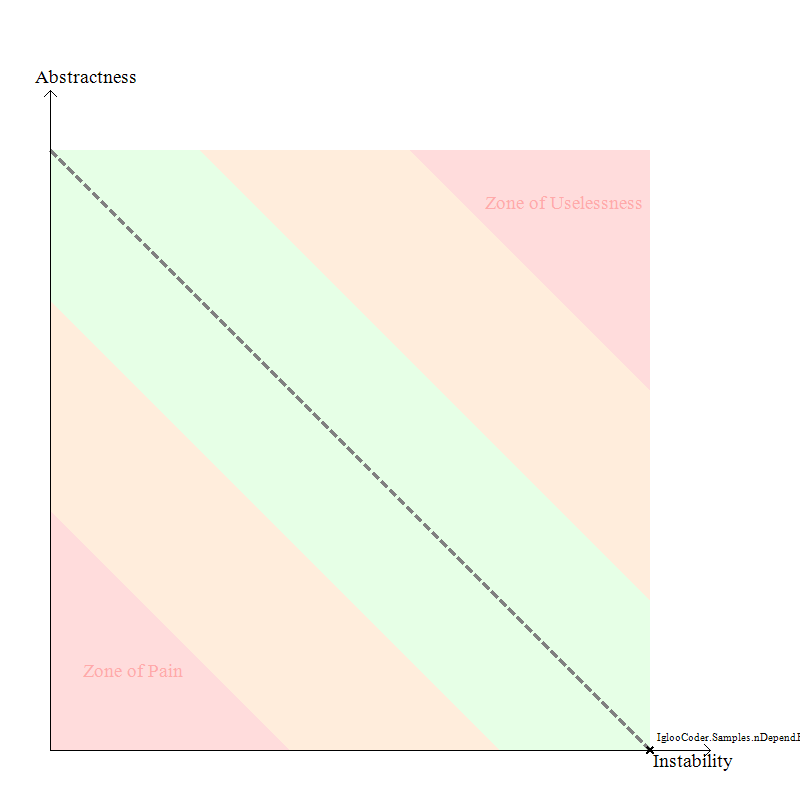 | This isn’t really all that shocking of code for most of us. The lack of shock isn’t because of the lack of egregious ignorance to good OO practices, but instead because we all to often see code written in this manner. What we have is a basic implementation of a customer, an address and a validation class. I suppose I could have taken this backwards on step farther and broken more OO best practices, by implementing the validation logic into the customer class itself. As you can see by the Abstractness vs. Instability image, this solution is firmly mired in the lower right corner which indicates that we have our code written completely to concretions and that it will have the worst possible resiliency to change. Essentially, when that inevitable change request or refactoring task comes in, you’re going to have a very hard time making them happen. |
Other things to note:
Abstractness == 0
Relational Cohesion == 1.33
Interface Based Code
 | I’ve always believed that one of the first steps to reducing the coupling in your code is to program to interfaces. When I start refactoring on an existing piece of code, creating interfaces is one of the first things that I do. I was quite surprised to see that simply changing to use this practice had such a significant impact on the Abstractness as reported by nDepend. Instead of being firmly pinned to the 0 value on the Abstractness axis, the code now evaluates at a reasonable 0.5, or half way up the scale. |
Other things to note:
Abstractness == 0.5
Relational Cohesion == 1.33
Single Responsibility Code
 | Adherence to the Single Responsibility Principle provides developers with code that is much easier to test, modify and read. During the refactoring that we did at work, this was one of the main principles that I drilled into my team. There are a few ways to tell if you have a poor following of SRP in your code. One of the easiest, but not always the most accurate, is class line count. If you have a large number of lines of code in your class, you probably have broken SRP. Another way to tell, but one that requires more thought, is if the complexity of your tests gets too high. The more dancing you have to do to setup or execute a test, the more likely you have abandoned SRP. |
Interestingly, my incremental implementations have caused the Abstractness of the solution to fall. Upon looking at the code, this is caused by the creation of the validation concretions in the CustomerValidator class. The resulting drop, from 0.5 to 0.33, is a result of these three “new” statements. Also note that the cohesion of the solution increased (not by much), but higher cohesion is usually a good thing.
Other things to note:
Abstractness == 0.33
Relational Cohesion == 1.67
Poor Man’s Dependency Injection Code
 | Because of a number of techno-political issues at work this is as far as I was able to take our refactoring. Poor Man’s DI is a cheap and dirty way to implement Dependency Injection. As you can see in the code, all that happens is that the concrete classes are injected into a parametered constructor through constructor chaining off of the parameterless constructor (see the CustomerValidator class for the implementation). |
None of the metrics change between this and the SRP implementation because we are still “newing-up” the three concretions in the code. All we have done is moved them from the method call to the constructor chaining. Abstractness of this solution stays stationary at 0.33.
Other things to note:
Abstractness == 0.33
Relational Cohesion == 1.67
Roll Your Own IoC Code
 | Please don’t judge me on my implementation of IoC. I was just doing what it took to get the concept across. It does work, and the implementation is stable, but there are some limitations. For instance, there is no ability for objects in the container to determine, and retrieve, objects that they may need in their constructors. That capability wasn’t needed for this sample so it didn’t get implemented (remember, code the simplest possible solution to meet your requirements). |
As you can see in the code, there still is the requirement to “new-up” the concretion. So all this implementation of Dependency Injection has done is move the concrete object creation to a different location in the code base. If this implementation of IoC were to work for a project, it would focus that concrete object creation into one central location, giving us one place for changes.
Even with what appears to be a direct movement of the object creation, this implementation did manage to increase the abstractness ever so slightly. More impressive was the significant increase in the Cohesion of the code base.
Other things to note:
Abstractness == 0.36
Relational Cohesion == 1.91
Castle Windsor IoC Code
 | Castle Windsor IoC is a fantastic product. It is the Ferrari to my IoC Lada. When you look through the code from this solution you will see that the only place that there is any “newing” up of concrete objects is in the test suite. Remember that I’m not including the test suite in the nDepend analysis runs. When I look at this code, I see it as being the best of all the implementations that I created here. That is mostly based on gut feeling, which is very different from what the metrics say. |
According to nDepend this implementation is on par with what was generated from the Single Responsibility solution. The biggest difference between the two is the change to implementing Inversion of Control.
Other things to note:
Abstractness == 0.33
Relational Cohesion == 1.33
Summary
When I first started this exercise I figured that there would be a steady progression towards a final, top level set of metric values. As there usually are with preconceptions, I was proven wrong. I found the most interesting thing to be that the implementation of Coding to Interfaces provided the largest single movement in the metrics. There is no doubt in my mind that this technique will never be a point that I allow negotiations or discussions to remove from a code base.
The second most interesting point was that there was little to no benefit (according to all the metrics) when implementing Dependency Injection. I know, in my gut, that this is the right thing to do. I’d even go so far as to say that implementing something like Castle Windsor or StructureMap is the only way to do it, but it still is interesting to see what the metrics say.
The third thing that struck a chord with me was that the change on the Abstractness vs. Instability graph (from the Base Code to the Poor Man’s Dependency Injection Code ) was about the same for this small piece of code as it was for the large project I analyzed at work. I figured that the complexity of a multi-project solution would have a bigger impact on the comparison of the results that it apparently did.
What’s the single biggest lesson that you can take from this? I’d probably have to say that my biggest lesson was the confirmation that static analysis metrics are not going to provide you with answers at all, let alone at a granular level. Instead they should be used as tools at a high level which provide guidance for your decisions. I also don’t think that you will be able to use them to compare projects.
If you have access to a tool like nDepend, and you’re thinking about taking on a project-wide refactoring, I’d suggest that you use the tool. It’s going to help you get started in the right direction and along the way it will provide feedback that, hopefully, confirms you are heading in the right direction.
Disclaimer: Although I was given a free license of nDepend by Patrick Smacchia, it was not in exchange for this blog post.